AI RAG Billing Assistant – Prompt Tuning, Feedback Form, Model Comparison
Taking over an existing LLM integration in a healthcare platform and making it reliable: cleaner prompt boundaries via LangChain, metadata-filtered RAG retrieval, a lookup table for arithmetic the model can't be trusted with, and a benchmark across seven models to back the choices with numbers.
An LLM integration that worked, sometimes
A RAG-backed assistant embedded in an internal platform, guiding clinicians through structured classification decisions — generating clarifying questions and candidate outcomes, and accepting corrections. It worked, but response consistency was uneven, the RAG context leaked irrelevant chunks into prompts, and a handful of answers depended on small pieces of arithmetic the model got wrong often enough to be a problem in a healthcare context.
The feedback path for clinicians was a single "!" button that ended the conversation — useful as a binary signal, useless for understanding why something went wrong.
Three targeted changes, each with a reason
LangChain for prompt boundaries. Introduced LangChain, which beyond cleaner code enforces a clean separation between system and user prompts. That alone improved response consistency measurably — the model was previously being given instructions and user content in a single blob, which is a known way to make behavior drift between runs.
Metadata-filtered RAG. The existing retrieval was returning semantically-close-but-contextually-wrong chunks. Switched the filter to route on document metadata first, then do similarity within the already-scoped subset. Fewer, more relevant chunks reach the prompt.
A lookup table for arithmetic. Some answers hinge on small numeric operations that LLMs still fumble unpredictably. For those, I moved the computation out of the model into a deterministic lookup and let the model do what it's good at — picking the right row.
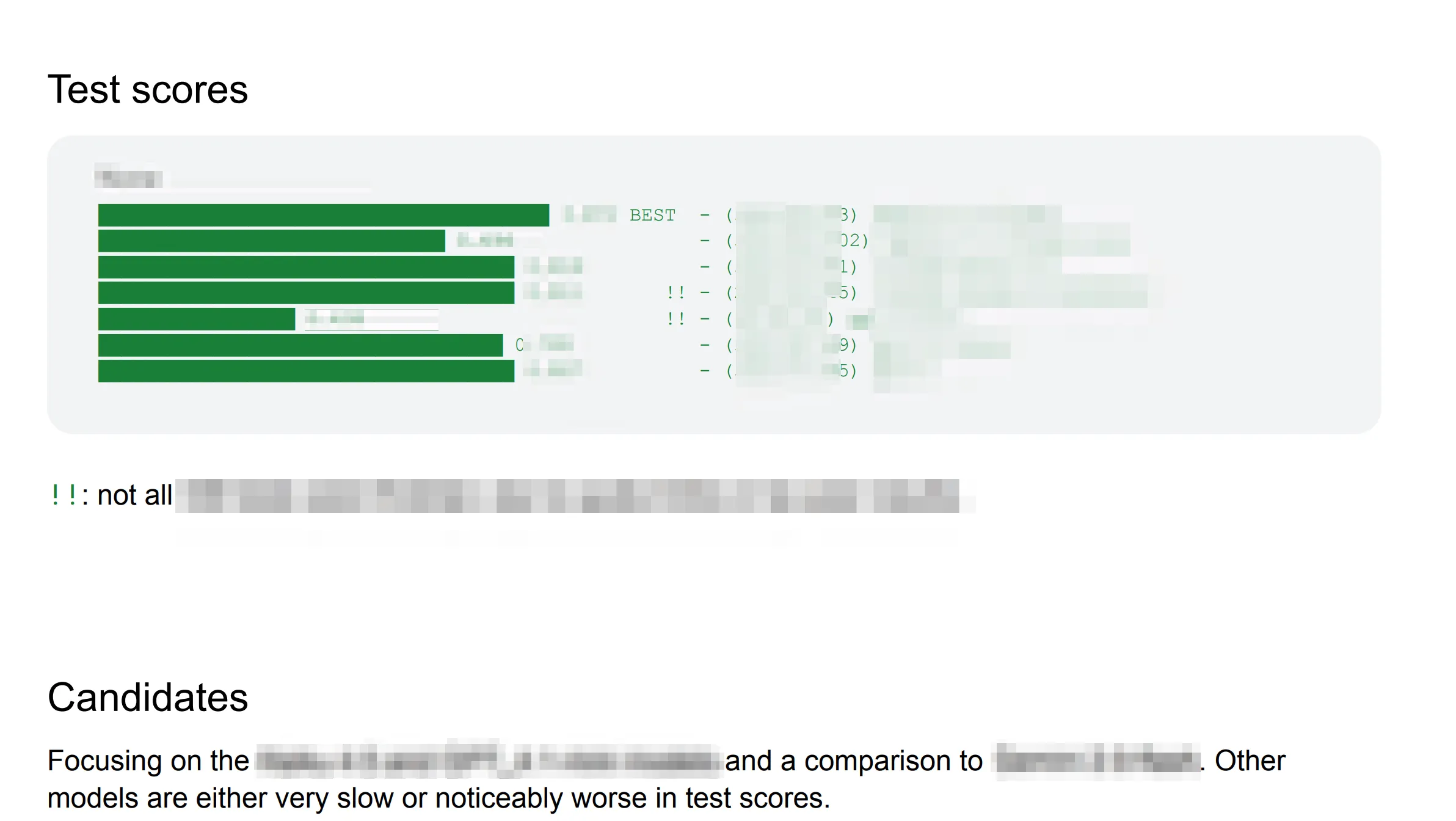
Seven models, three providers, actual numbers
On my own initiative, built a benchmarking harness and evaluated seven models across Claude, GPT and Gemini families against a curated test set. Accuracy, consistency, latency, and cost — reported side by side so the model choice is a decision with a paper trail rather than a preference.

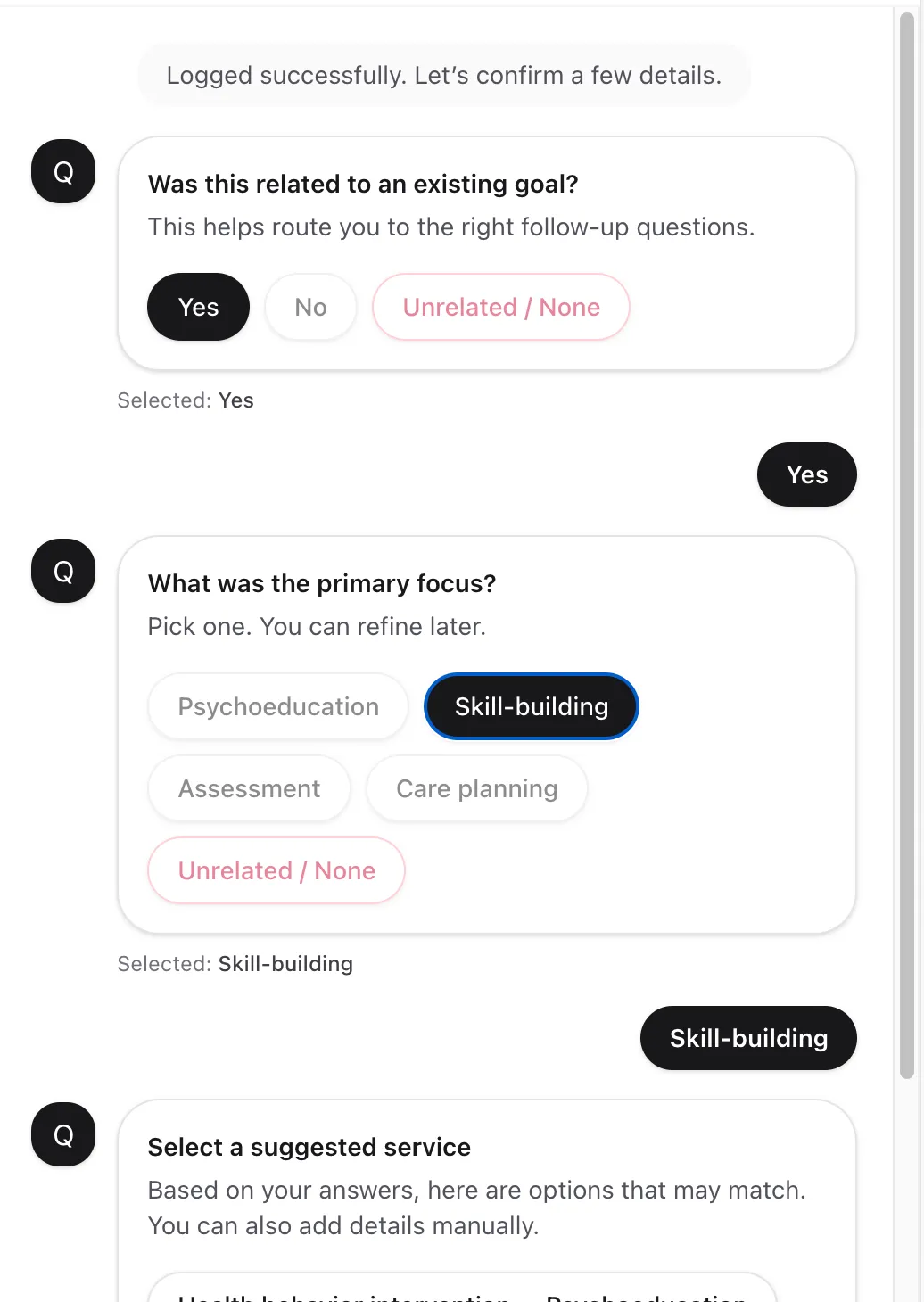
From a "!" button to a structured signal
Replaced the minimal "!" button with a structured form capturing issue type (question doesn't make sense · answer choices don't make sense · other) plus free-text details. That turned an opaque binary into actionable feedback the team can categorize and act on.
Every interaction is fully audited: questions asked, answers given, retries, feedback submitted. In a HIPAA-bound environment, "we can reconstruct what the model was asked and what it said" is not optional.
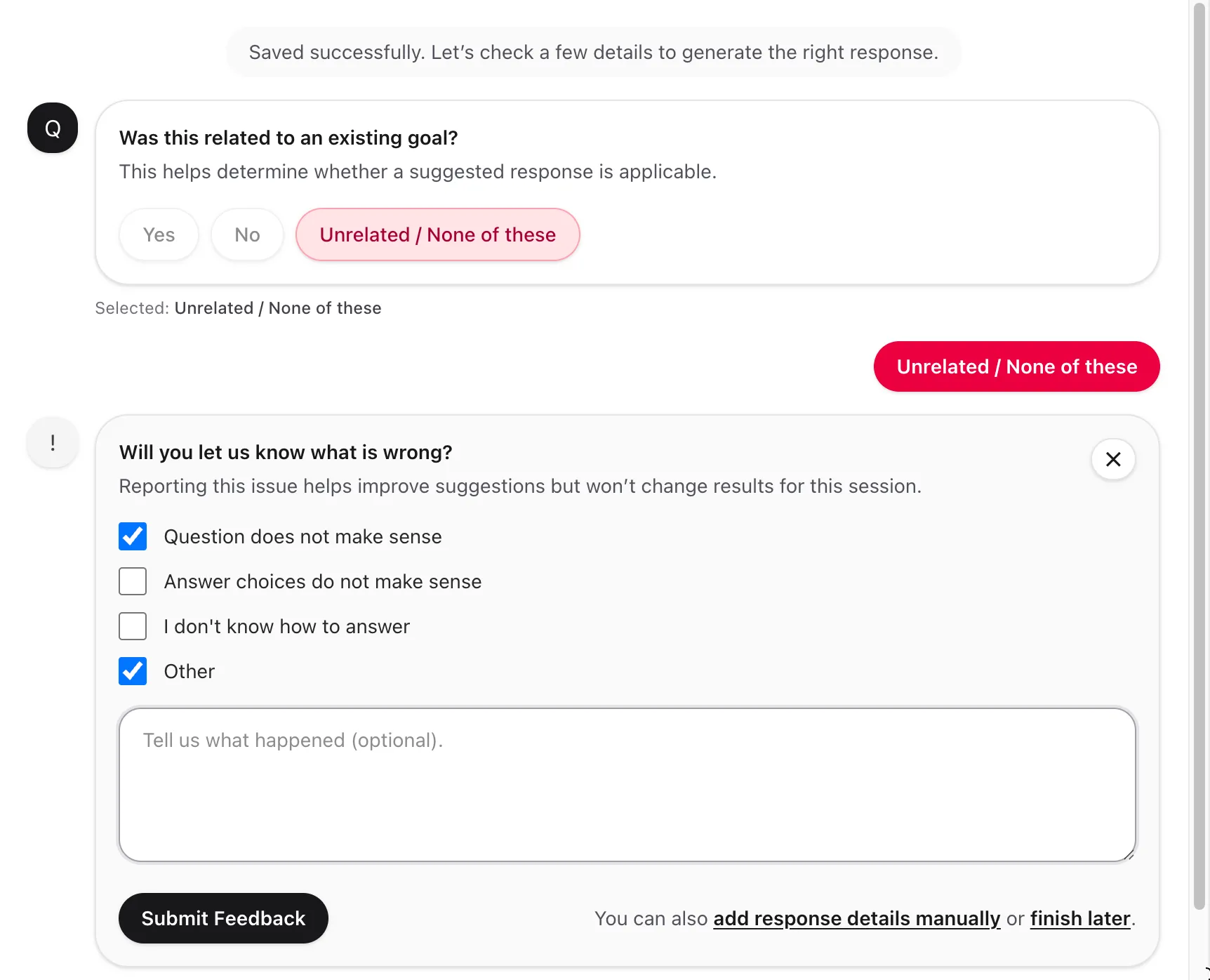
What the work covered
| surface | covers |
|---|---|
| prompt | LangChain · separated system / user roles · templated structure |
| retrieval | metadata filter first, similarity second · fewer, more relevant chunks |
| accuracy | deterministic lookup table for small-arithmetic answers |
| benchmark | 7 models · 3 providers · accuracy · consistency · latency · cost |
| feedback | structured form (issue type + details) · fully audited interactions |