HydroPower Bidding Platform
A ~14-month engagement on the bid-processing pipeline that generates and submits daily electricity-market bids for hydropower operators — fan-out solver runs, resilient aggregation, and a workflow engine doing 1,300+ orchestrated runs a day across clients.
The daily bid deadline doesn't slip
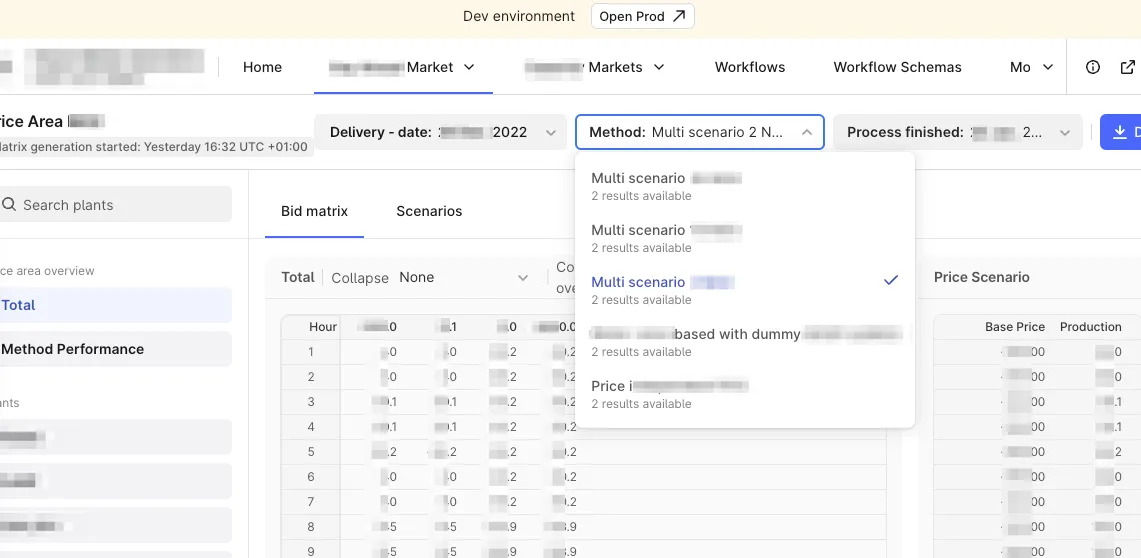
Electricity markets close bid submissions at the same time every day. For hydropower operators, missing that window is expensive, and bid quality is a direct function of how many scenarios you can solve before it. The platform had to produce a validated bid matrix per asset, per day, for each client — idempotent, observable, and fully automated, with enough signal to diagnose any run after the fact.
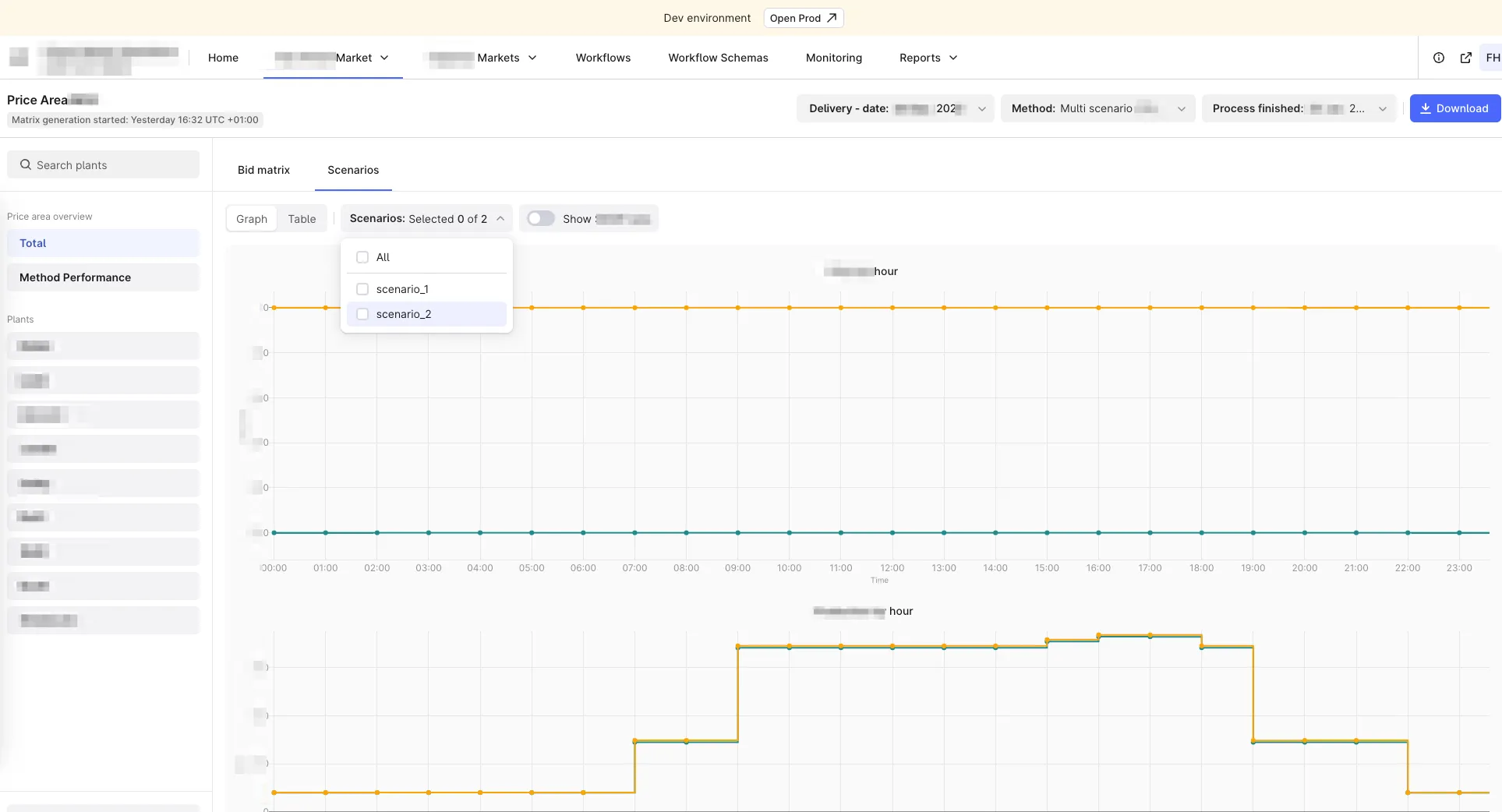
Fan-out, collect, aggregate
Dispatcher. Evaluates configuration at runtime and produces a task list whose length depends on the scenarios to cover. The workflow engine expands it into parallel function executions — no code change required to add or remove scenarios.
Solvers. Idempotent Python functions, one per scenario, each with explicit status tracking and structured event metadata. Re-running the same solver with the same inputs produces the same outputs and the same audit trail.
Aggregator. One per asset: collects partial bid outputs across scenarios and reconciles them. Many of these feed a single bid-matrix submission, so the aggregator has to handle partial-output cases explicitly rather than failing the whole run — one stuck asset shouldn't take down the fleet's daily submission.
Graceful degradation, not stoic silence
A daily cadence with a hard deadline makes the failure model the product. Stratified execution timeouts were set per stage — short for dispatch, longer for simulation, moderate for aggregation — so failing stages fail fast and slow stages aren't cut off mid-work. If every solver run failed, the system raised alerts and preserved the context needed to diagnose. If only some runs failed, it marked partial outputs and continued aggregation when safe to do so, rather than silently dropping the whole bid.
Migrating to a flexible domain model
My largest piece of work was leading a migration from the legacy data models to a flexible domain-modeling approach. That meant refactoring data access, redefining function inputs and outputs across the pipeline, and removing the legacy transformation paths that had accumulated. The result was a codebase where operator-facing schema changes stopped forcing changes through the orchestration code.
Around that, I built out integration testing infrastructure — fixture-driven test cases, mocks for external approvals — consolidated components into a monorepo, and refactored core sections of the bid-matrix pipeline for maintainability. Beyond the pipeline itself, I contributed to shared developer tooling and libraries used across the platform: SDK improvements, code-generation utilities, solver-adjacent wrappers, and domain schema work.