A Python tool that extracts structured data from scanned and photographed PDF documents published by Romanian forest districts (ocoale silvice). These are timber auction announcements that forest districts are legally required to publish before selling timber, regulated under HG 715/2017.
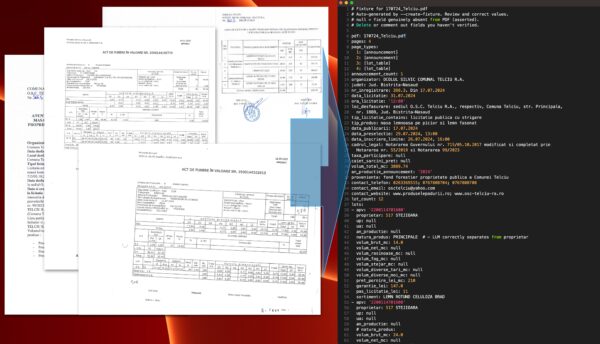
The challenge: every forest district uses its own format. The PDFs are all photographed or scanned physical papers. Layouts vary wildly across 16+ counties. Some are clear, some are faded, some have tiny fonts or rotated pages. The data inside is tabular: lot numbers, tree species, timber volumes, assortments, starting prices, locations. But there’s no consistent structure to rely on.
The extraction runs as a multi-pass pipeline, each pass building on the previous one and saving intermediate artifacts for auditability:
– **Pass 1**: Detect and correct page orientation (scanned pages are often rotated).
– **Pass 2**: Raw transcription of the document content.
– **Pass 3**: Structured table transcription.
– **Pass 4**: Map the raw transcription into a structured lot schema (species, volumes, assortments, prices).
– **Pass 5**: For any values marked as uncertain in earlier passes, re-render the page at 400 DPI and re-extract just those values for higher confidence.
– **Merge**: Combine all pass outputs into final structured YAML and CSV.
This multi-pass design evolved because single-pass extraction proved prone to hallucinations and unreliable reads. Each pass narrows the problem: orientation first, then raw text, then structure, then semantics, then targeted re-reads for anything still uncertain. The intermediate outputs at each step make debugging and validation straightforward.
The LLM is Claude (API in production, Claude Code interface during development to save on API costs during iteration). A multi-step validation process catches hallucinations: structured output schemas, cross-referencing between passes, and confidence scoring that triggers the high-DPI re-read pass.
Testing uses pytest for both unit and integration tests. Integration tests call the actual Claude API and compare against validated expected outputs. The responses turned out to be stable enough for this to work as a reliable regression suite.
Output is YAML and/or CSV. Built for a SaaS platform aggregating Romanian forestry data. The extractor will be integrated into their scraping pipeline, with similar modules planned for other document types.