A RAG LLM-powered assistant embedded in an internal platform to guide users through structured classification decisions. The assistant generates a structured set of clarifying questions and candidate outcomes, supports user corrections, and logs feedback for continuous improvement.
I took over an existing LLM integration and made several improvements. Introduced LangChain, which beyond cleaner code also improved response consistency by properly separating system and user prompts. Improved the RAG-style context filtering (metadata-based). Built a lookup table to address deficiency in math capability of the model
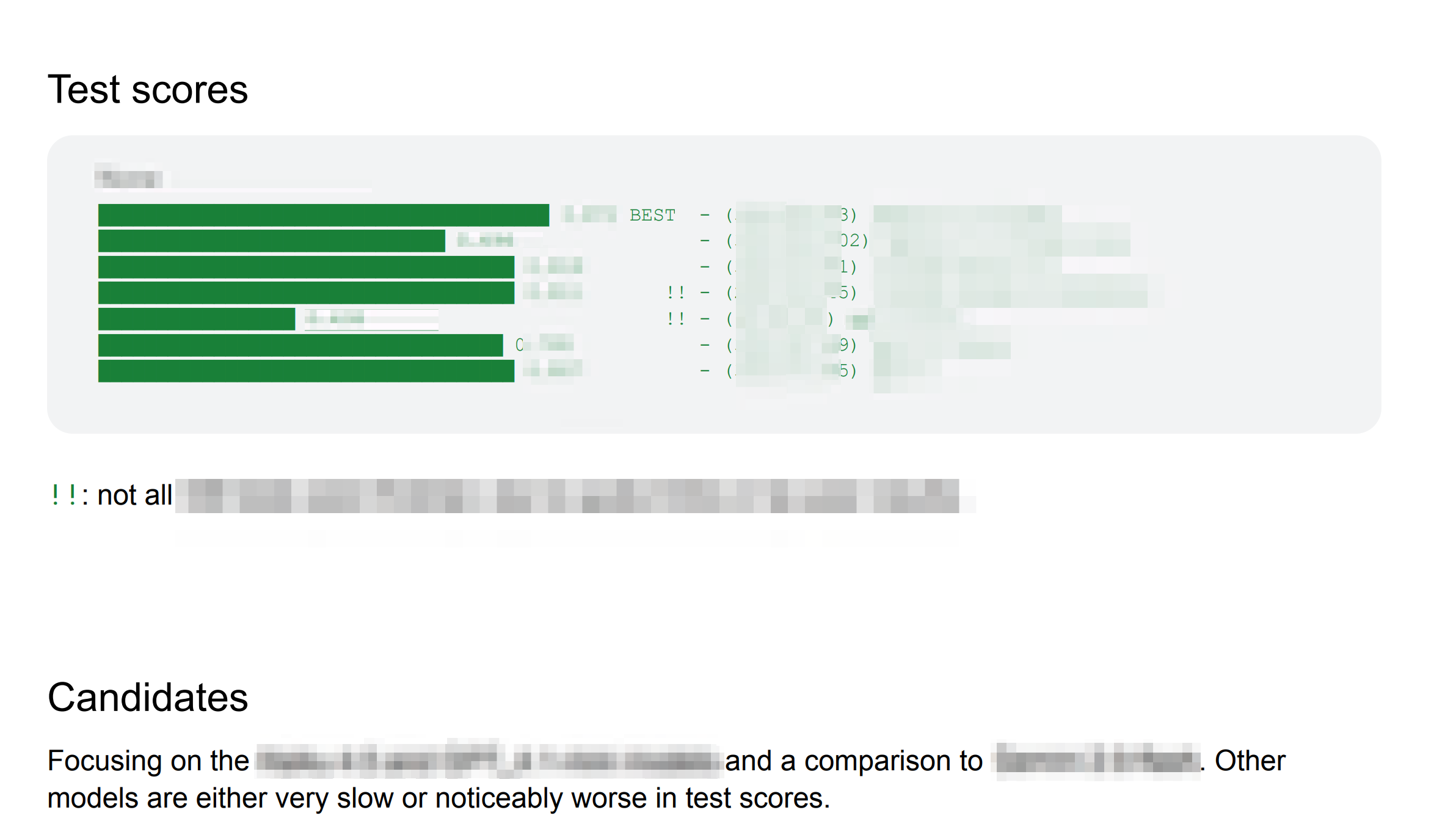
Benchmarked across seven models on my own initiative. Total of 7 models from multiple providers were tested.

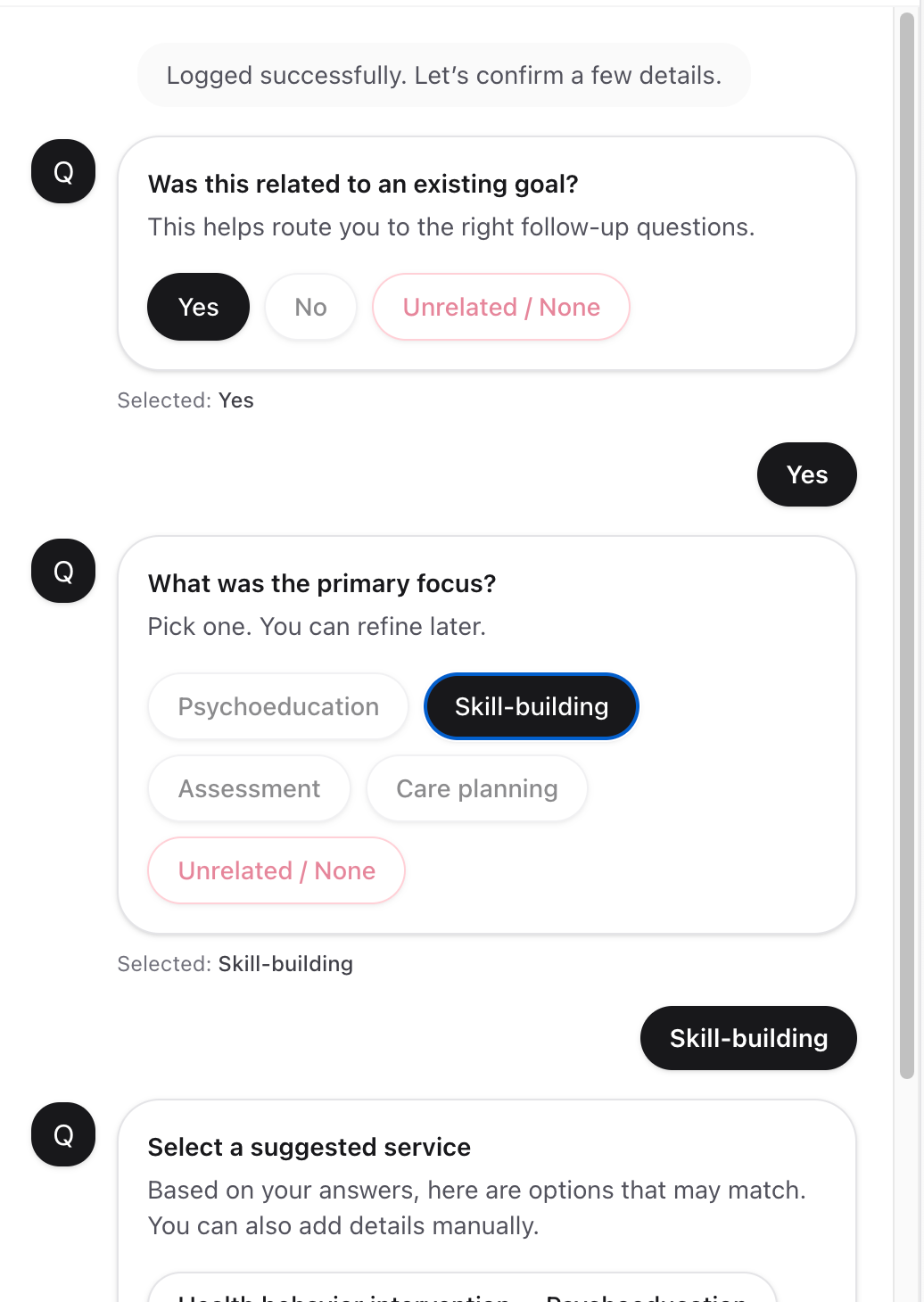
Enhanced the clinician feedback flow from a minimal “!” button that ended the conversation, to a structured form collecting issue type (question doesn’t make sense, answer choices don’t make sense, other) with free-text details. Every interaction is fully audited: questions asked, answers given, feedback submitted, retries.

Client name and identifying details withheld due to confidentiality. Screens and data are recreated/illustrative; no proprietary assets included.